

从噬菌体展示到扩散模型:抗体亲和力成熟的AI进化之路
从噬菌体展示到扩散模型:
抗体亲和力成熟的AI进化之路
作者:贝叔 | 且来山笔记
一位做抗体工程的读者给贝叔留言,希望了解AI模型预测亲和力的靠谱程度到底如何,部署这些模型需要多大的算力投入。这两个问题恰好触及了当前AI抗体工程最真实的焦虑——纸上效果好,落地行不行?必须马上安排!
抗体亲和力成熟(Affinity Maturation, AM)是抗体工程中最关键也最昂贵的环节。传统方法依赖展示技术加多轮筛选,耗时数月、花费巨大。诗曰:文章本天成,妙手偶得之!
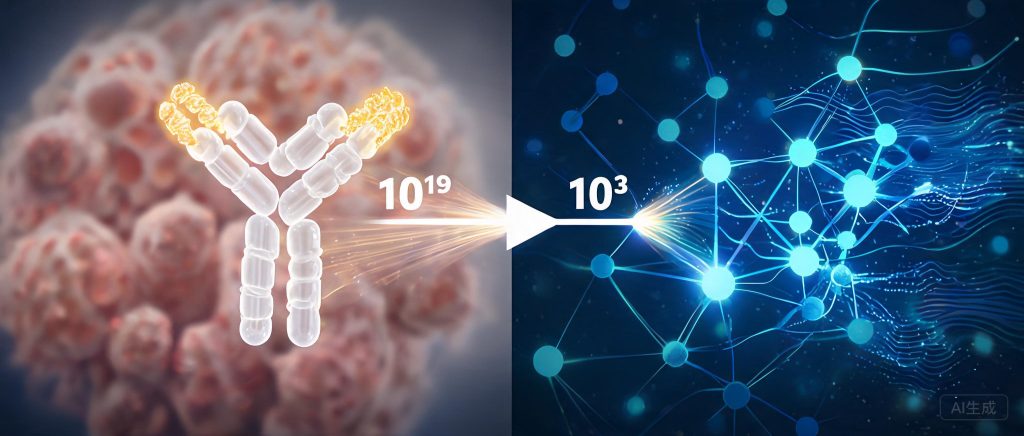
从一个数字开始:一个典型的CDR H3区域约有15个氨基酸残基,其序列空间是2015 ≈ 3.3×1019,19个0!而即使容量最大的噬菌体展示技术,能够筛选的序列空间也只有1012。从1019种序列中,找出亲和力最好的那一株,相当于在地球上所有的沙子里找一粒特定的金色沙粒。
AI的目标很清晰:通过在计算机中预判哪些突变组合最可能提高亲和力,把实验筛选空间从1019压缩到103-105量级。本文聚焦AM这个更窄但更现实的战场:从生物学原理到AI模型,从数据瓶颈到算力壁垒,逐一拆解。
第一章:什么是亲和力成熟——从免疫学原理说起
亲和力是抗体抓住抗原的强度,足够高的亲和力决定了抗体的捕获抗原效率和发挥效应功能的能力。亲和力成熟是抗体持续发生序列优化、逐渐提高亲和力的过程。体细胞超突变(SHM)是亲和力成熟的分子基础;抗原选择性筛选是亲和力成熟的闸门。
在淋巴结/脾脏生发中心(Germinal Center)内,B细胞经历”暗区-明区”的循环:暗区中,AID酶(Activation-Induced Cytidine Deaminase)在抗体可变区基因中引入高频点突变,且靶向特定核苷酸基序——尤其是WRCY热点基序(W=A/T, R=A/G, Y=C/T);明区中,抗原与B细胞表面的BCR结合提供选择信号,高亲和力克隆获得更强的增殖信号。
这个过程的效率惊人:人体内SHM通常在2-4轮突变+选择后实现10到1000倍的亲和力提升。
亲和力成熟的主战场是CDR H3,为什么是这个区域呢?CDR H3贡献了抗体-抗原结合面积的60-70%,其长度和构象多样性也最大,这源于V-D-J重组的随机性。CDR H3没有固定的骨架模板,构象高度灵活,在传统亲和力成熟方法、以及基于AI的抗体改造过程中,都带来了极大挑战。
第二章:传统的三种亲和力成熟技术
抗体研发过程中的亲和力成熟,即在体外模拟体细胞超突变和抗原筛选的过程,获得满足要求的抗体序列。传统实验方法围绕三大展示技术展开,各有明确的边界。
| 维度 | 噬菌体展示 | 酵母展示 | 哺乳动物细胞展示 |
|---|---|---|---|
| 文库容量 | 1010-1012(最大) | 108-109 | 105-109 |
| 典型周期 | 2-4周 | 3-6周 | 4-8周 |
| 可展示形式 | Fab/scFv/VHH(无全长IgG) | IgG/Fab/scFv/VHH | IgG全格式+双抗 |
| 翻译后修饰 | 无真核修饰 | 非哺乳动物糖基化 | 正确的哺乳动物PTM |
| 功能性筛选 | 受限 | 受限 | ADCC/CDC可行 |
| 已上市抗体数 | 17+ | 较少 | 增长中 |
噬菌体展示文库容量最大、成本最低,但原核系统缺乏真核翻译后修饰,无法在全长IgG格式下筛选。酵母展示提供了定量FACS筛选能力,但糖基化模式与人类不同,文库容量也受限于转化效率。哺乳动物展示最接近最终药物形式,但成本最高、周期最长。
更根本的问题是三者共享的瓶颈:
1. 序列空间鸿沟:1019的理论空间 vs 1012的最大文库容量,差了7个数量级
2. 局部最优陷阱:每轮筛选只选最好的,可能错过需要两步协同突变的组合(上位效应/epistasis)
3. 多目标冲突:亲和力提升常以牺牲稳定性和表达量为代价
4. 黑箱问题:从文库中命中目标后,难以理解”为什么这个突变有效”
第三章:AI介入的数据基础——有什么数据可用?
AI模型需要数据,但亲和力成熟需要的数据非常特殊:不是”所有抗体序列”,而是“同一抗体的野生型+突变体+对应亲和力数值”——理想格式是(wild_type_sequence, mutant_sequence, ΔΔG or KD_ratio)。这比通用抗体序列稀缺得多。
| 数据集 | 规模 | AM任务价值 | 局限性 |
|---|---|---|---|
| SAbDab | 8万+抗体结构 | 提供结构上下文 | 复合物结构仅~9600条,AM配对数据极少 |
| OAS | 10亿+序列 | 序列分布参考 | 无功能标注,无法用于监督学习 |
| SKEMPI | 7,085个突变+ΔΔG | 直接适用于训练 | 非抗体专用,抗体条目有限 |
| AbBiBench | 184,500+条实验测量 | 较新统一基准 | 覆盖14种抗体、9种抗原 |
| AbRank | 381,713条结合实验 | 成对排序评估 | 预测值非实测值 |
数据面临三大核心挑战:稀缺性(高质量AM配对数据全球可能只有数千到数万条)、不可比性(不同实验室的KD值因实验条件差异难以合并,Kd值跨度达108倍)、数据泄漏风险(训练/测试集划分时,同一抗体家族序列可能同时出现在两边——PDBbind-CASF事件已证实”伪理解”问题的严重性)。
PDBbind-CASF事件,是2024-2025年在计算药物设计领域曝出的大规模训练-测试数据泄露(train-test leakage)危机:PDBbind训练集与CASF测试集高度重叠/同源,导致几乎所有深度学习打分模型在CASF上的”顶尖性能”都是虚高、不可靠、泛化能力被严重高估;为解决泄露问题,研究者提出PDBbind CleanSplit,用结构聚类+序列去同源算法,严格剔除训练集中与CASF相似的所有样本。
简而言之:AM任务面临的是经典的”小数据+高维特征”难题。
第四章:AI模型军备竞赛——谁在领跑?
这是全文技术密度最高的部分。我们按方法分类而非时间顺序组织,聚焦AM专用或直接相关的模型。
方法分类
| 类别 | 代表模型 | 核心思路 | 成熟度 |
|---|---|---|---|
| 基于结构的图神经网络 | GearBind (Nat Comm 2024) | 3D结构编码为图,预测突变效果 | ★★★★ (有湿实验验证) |
| 生成式模型 | MAGE (Cell 2025), IgGM (ICLR 2025) | 生成满足亲和力约束的CDR序列 | ★★★ (前沿但验证有限) |
| 核苷酸上下文模型 | Thrifty (PLOS CB 2025) | 利用SHM核苷酸热点特征预测AM效果 | ★★★☆ (轻量高效) |
| 大语言模型迁移 | AbLang-2, IgLM | 抗体序列预训练,下游微调AM | ★★★☆ (通用性强) |
| 从头设计(背景参考) | RFantibody (Nature 2025) | 扩散模型生成全新抗体可变区 | ★★★★★ (非AM专用) |
三个代表性模型
GearBind — 结构信息比序列信息更有预测力
百奥几何团队发表于Nature Communications 2024,将抗体-抗原复合物的3D结构编码为多关系原子图(顺序边+径向边+KNN边),通过多层级消息传递(原子层→边层→残基层)预测突变后的结合自由能变化。核心优势:在困难目标(零相似样本)上PearsonR达到0.707,远超FoldX的0.411。实验验证中,仅测试20个候选即实现17倍亲和力提升。启示:结构信息是AM预测的关键变量,但也意味着模型依赖准确的复合物结构输入。
MAGE — Cell级别的生成式突破
范德堡大学Georgiev团队发表于Cell 2025,基于ProGen2-base(7.64亿参数)微调,仅需抗原氨基酸序列即可从头生成配对的重链-轻链。SARS-CoV-2 RBD上45%结合命中率(9/20),最强中和抗体IC50=6.7 ng/mL。但需要注意:MAGE是从头设计工具,训练数据仅含二值化结合标签,不保证高亲和力——与AM优化是不同的问题。
Thrifty — 小模型的大智慧
Fred Hutchinson癌症中心发表于PLOS Computational Biology 2025,这项工作可能被低估。仅5931参数的Thrifty-SHM模型,利用SHM的核苷酸上下文(WRCY热点基序)作为特征,在预测突变位点和氨基酸结果上全面优于4500万参数的AbLang-2和6.5亿参数的ESM-1v。
原因很优雅:SHM由AID酶驱动,优先靶向特定核苷酸基序。这种突变偏向性在核苷酸层面才能被精确捕捉——蛋白质语言模型(在氨基酸层面操作)完全丢失了这些信息。
第五章:多目标优化的真正困局
抗体药物开发不是单目标优化——只看亲和力是不够的。
| 优化目标 | 与亲和力的关系 |
|---|---|
| 表达量 | 常负相关 ↑ |
| 稳定性(Tm) | 可能冲突 ↑ |
| 免疫原性 | 突变可能引入新T细胞表位 ↑ |
| 溶解度/聚集倾向 | 高亲和力突变常降低溶解度 ↑ |
现实中有三种妥协策略:分阶段优化(先保亲和力后修可开发性,最常用但易陷入局部最优)、约束优化(设定阈值如Tm > 65°C再最大化亲和力)、Pareto前沿搜索(理想方案但对数据要求最高)。
AbNovo(ICLR 2025)是首个将多目标抗体设计形式化为约束优化问题的框架,以结合亲和力为奖励信号,同时对特异性、自缔合性、稳定性施加显式约束。方向正确,但离工业落地仍有距离。
第六章:算力壁垒——公司该怎么选
回到读者最关心的问题:部署这些模型到底需要多大算力?
| 模型类型 | 代表 | 推理硬件 | 训练门槛 |
|---|---|---|---|
| 大语言模型 | ESM-2 (15B) | 多GPU/云服务 | 极高 |
| 图神经网络 | GearBind | 单GPU可推理 | 中等 |
| 扩散模型 | RFantibody | 多GPU | 高 |
| 轻量专用模型 | Thrifty (5931参数) | CPU可运行 | 低 |
Thrifty的存在对中小Biotech是个好消息:AM任务的数据特征(SHM核苷酸热点)足够强,小模型抓住核心特征即可达到近似效果。另一个关键洞察:推理≠训练。大多数公司不需要自己训练模型,使用预训练模型推理的算力门槛远低于训练。结构信息的代价也值得注意:GearBind需要3D结构输入,获取结构数据(冷冻电镜/同源建模)的成本可能高于计算本身。
务实建议:小型Biotech从Thrifty类轻量模型起步,结合少量湿实验验证;中型公司部署GearBind类GNN模型,投入同源建模获取结构;大型药企可考虑扩散模型全流程,但需配套自动化实验室。
第七章:从代码到临床
AI模型预测的ΔΔG与实验KD变化的相关性通常在r = 0.3-0.7之间。计算机里完美的突变在细胞实验中可能完全不表达——”纸上谈兵”风险真实存在。
但产业化正在加速。Generate Biomedicines的GB-0895是全球首款进入III期的AI设计抗体:靶点TSLP(气道炎症关键因子),AI优化了超高亲和力、约89天半衰期和高特异性,实现每6个月皮下注射300mg。从设计到III期仅4年,III期试验SOLAIRIA-1和SOLAIRIA-2覆盖约1600人、40+国家。Absci的ABS-101靶向TL1A治疗炎症性肠病,从概念到I期仅2年(行业平均5.5年),2025年5月首例给药。
| 项目 | 靶点 | 阶段 | 关键数据 |
|---|---|---|---|
| GB-0895 | TSLP | III期 | 半衰期~89天,每6个月给药,4年从设计到III期 |
| ABS-101 | TL1A | I期 | 2年从概念到临床,2025/5首例给药 |
结语
回扣开头的”十亿分之一的赌注”——这个概率问题没有被完全解决,但搜索空间已经被大幅压缩。亲和力成熟的未来不是AI vs 湿实验的二选一,而是AI × 湿实验的双向赋能。对研发人员来说,学会解读AI模型的输出,理解其置信区间和局限;对管理者来说,投资数据基础设施,挖掘实验室中高质量AM配对数据,价值不可限量。
黄金突变一直都在那里。区别在于,以前我们需要筛遍整个沙漠才能找到它;现在,AI给了我们一张藏宝图,尽管这张图还不够精确——我们仍在绘制它的过程中。
参考来源
1. GearBind: Cai H, et al. Nature Communications 15:7785 (2024)
2. RFantibody: Bennett N, et al. Nature (2025)
3. MAGE: Wasdin PT, et al. Cell 188(25):7206-7221 (2025)
4. Thrifty: Johnson MM & Matsen FA IV. PLOS Computational Biology 21(12) (2025)
5. IgGM: Yao JH, et al. ICLR 2025
6. AbNovo: Ren M, et al. ICLR 2025
7. AbBiBench: arXiv:2506.04235 (2025)
8. AbRank: arXiv:2506.17857 (2025)
9. SKEMPI 2.0: Jankauskaitė J, et al. Bioinformatics (2019)
10. 哺乳动物展示综述: Frontiers in Immunology (2024)
11. 数据泄漏: Nature Machine Intelligence (2025)
12. GB-0895: Generate:Biomedicines官方新闻稿 (2025年12月)
13. ABS-101: Absci NASDAQ新闻稿 (2025年5月)